
アダルト可能!漫画 吹き出し テキスト抽出のやり方と便利ツール5選 漫画の構成を読まずに分析するツール
漫画セリフを自動書き起こしする方法|2026年最新の特化OCRと副業活用ガイド
漫画のセリフを一本一本打ち込むあの地獄みたいな作業、正直もう終わらせませんか。
あなたが今この記事を開いたのは、たぶん「手作業で書き起こしてる時間をコンテンツ量産に回したい」っていう、口には出さないけど確実にある本音のせいだと思うんですよね。
2026年4月現在、漫画OCRはついに「実務で使えるレベル」に到達しました。
この記事では、僕が実際に触って検証した最新ツールと、明日から使える具体的な自動化フローを、ぶっちゃけベースで全部出します。
最後には、PDF形式や画像形式でドラッグ&ドロップで漫画を理解して漫画の中身、シーンの流れなどを分析し、さらにその分析データを元に再構築する方法も解説していきます。
つまり漫画そのもののデータを抽出して、その流れを土台にして、セリフとキャラクターを再構築する‥実は今、脚本スキルゼロの初心者が、そういうツールを利用して漫画や小説を製作して稼ぐ人が増えているんです。
この記事で分かる事。
- 漫画のセリフを書き起こすツールの存在。
- 漫画の縦書きも書き起こすツールの存在
- 漫画を分析して各シーンの流れ目的を抽出して再構築するツールの存在
この記事で解説していきます。
漫画セリフ書き起こし自動化が実用域へ到達した理由
少し前まで、漫画のセリフをOCRにかけると、まともに読める形では出てこなかったんです。
Google Vision APIのような汎用OCRは、縦書き・ルビ・手書き風フォント・吹き出しの歪み、このあたりで一気に崩れてました。
それが変わったのが、2025年後半から最近にかけての「漫画特化モデル」の登場です。具体的には、PaddleOCR-VLをManga109-sと150万件の合成データでファインチューニングした「PaddleOCR-VL-For-Manga」が、完全文認識精度を27%→70%まで引き上げました。
数字で見ると地味に感じるかもしれませんが、実運用では世界が変わるレベルです。
27%精度とは「1文のうち3割しか合わない」状態で、後工程の人手修正がほぼ写経に近いレベル。70%まで上がると「軽く直せば使える」領域に入り、作業工数がだいたい1/5〜1/10に圧縮されます。
縦書き・ルビ・吹き出しに強い特化モデルが続々登場
もう1つの主役が、kha-white氏が公開している「manga-ocr」です。
Transformers系のVision Encoder Decoderで組まれていて、縦書き横書き混在、ルビ、画像上の文字、低解像度スキャン、このあたりに設計レベルで耐えるよう作られています。
Apache-2.0ライセンスなので、商用利用OK(※扱う画像の権利は別問題、後述します)。吹き出し1個をまるごと一括でテキスト化できる「マルチライン一括推論」が強く、行ごとに切らなくていいのが神仕様なんですよね。
ですが、これも実装しましたが、無理でした。
と言ってもセリフのテキストばかり読み込んでも意味がないんです。
なぜならセリフを起こして作品の流れ、つまり骨組みを抽出することが最も重要で、「読んで楽しみたい」だけなら読めばいいです。
しかしビジネス目線で考えると、「作品の全体像を把握するためにセリフを抽出して分析したい」のです。
セリフ書き起こしが副業で武器になる理由
グローバルWebtoon市場は2032年に710億ドル、年率30.6%成長という試算が出ています。
つまり「セリフを抽出して加工する」こと自体がコンテンツ産業の上流工程に直結しているわけで、個人でもここを自動化できる人は単純にレバレッジが効きます。
ここで1つ、行動経済学の「取引コスト理論」をさらっと挟んでおきます。手作業という摩擦が消えた瞬間、やらなかったことが一気にビジネス化される——これは過去あらゆる自動化で起きた流れで、漫画OCRも完全に同じ位置にいます。
この書き直し的なやつは、ブログやサイトでいうと「ブログ記事の構造を理解して異なる文章に書き換える」このロジックと理屈は同じです。
何より嬉しい事が、
「スキルや資格、そして肩書も実績も不要」という点です。
目的別で選ぶ漫画セリフOCRツール比較
「結局どれ使えばいいの?」って話を最初にやります。結論、用途で4つに分かれます。
手軽重視はGUIで完結するノーコード系OCR
非エンジニアなら、UPDFやGoogleドキュメントのOCR機能で十分戦えます。画像を右クリック→「Googleドキュメントで開く」でテキスト化→ChatGPTに流して整形、この3ステップで軽い案件は回ります。
ただし縦書き精度は漫画特化モデルに明確に劣ります。正直、業務で使うなら「下書き生成ツール」として割り切るのが正解です。
大量処理に強いmanga-ocr(kha-white製)
Hugging Faceでホストされていて、pipで一発導入できるのが最大の強みです。Google ColabでもローカルMacでも動きますし、Apple Silicon最適化された派生CLIもZennで公開されてます。
- pip install manga-ocr で即導入可能
- 縦書き・ルビ・低画質・画像上の文字すべて対応
- 吹き出し単位でマルチライン一括認識
- Apache-2.0ライセンスで商用利用が可能
縦書きの漫画は、試したけど無理でした。
高精度重視ならPaddleOCR-VL-For-Manga
VLM(視覚言語モデル)ベースなので、単に文字を拾うだけじゃなく「吹き出し内の文脈」まで踏まえて認識します。スタイライズされたフォント、派手な効果フォント、ここに強いのが実使用での実感です。
ベースがPaddleOCR-VLで109言語対応なので、翻訳パイプラインの中核に据える前提なら第一候補です。RTX 3060(12GB)でファインチューニングを再現した事例もGitHubに出てて、自前の画風に合わせたチューニングまで射程に入ってます。
全自動重視ならパイプライン型Webアプリ
画像D&Dから脚本抽出→音声合成まで一気通貫でやるボイスコミック自動化アプリも出そろいました。ComicsMaker.aiのようにコマ割りとセリフ配置まで面倒見るサービスや、吹き出し配置を自動最適化するツールも最近増えていますが、英語かつサブスクで、個人的には「使いにくいな」が率直な意見です。
とはいえ技術が発達していることは確かです。

結局、どれから触ればいいんですか?手を広げすぎて迷子になりそうで。
 羽田義和
羽田義和ぶっちゃけ最初はmanga-ocr一択でいいです。無料、導入5分、精度も実務レベル。そこから必要に応じてPaddleOCR-VL-For-Mangaに乗り換える流れが一番コスパ良いですよ。
とにかく1つに絞って手を動かすのが、迷子にならない最短ルートです。
漫画OCR自動化パイプラインの内部構造を理解する
ツールの中で何が起きているか、ここを知ってるかどうかで精度のチューニング力が変わります。
仕組みはざっくり6工程です。
- 吹き出し検出:セグメンテーションモデルでテキスト領域を抽出
- コマ推定:DBSCANなどで領域をクラスタリングし、パネル単位にグループ化
- 読み順推定:日本漫画の「右上→左下」ルールに沿ってソート
- OCR処理:manga-ocrやPaddleOCR-VL-For-Mangaで吹き出しごとにテキスト化
- 後処理:抽出済み領域を黒塗りして再抽出、重複除去
- 構造化出力:コマ番号・話者推定・セリフをJSON/CSVに格納
この6工程を全部1つのアプリが面倒見てくれるのが全自動系、上流3工程を自前で組んでOCR部分だけモデルに投げるのがプロ運用、みたいな棲み分けになっています。
初心者でも失敗しない漫画OCR導入手順
ここからは具体的な手順です。レベル別に3ルート用意しました。
GUI派ルート:非エンジニアでも30分で回る手順
Googleドキュメントの画像OCR機能で素材を一括テキスト化し、ChatGPTに「セリフだけ抜き出してコマ番号を振って」と投げる、これだけで下書きができあがります。
- 素材画像をGoogleドライブにアップロード
- 右クリックで「Googleドキュメントで開く」を選びテキスト化
- 抽出テキストをChatGPTに渡してセリフ整形・話者推定
- Spreadsheetにコマ番号とセリフを格納してDB化
精度は60%程度ですが、下書き目的なら十分実用になります。
中級者ルート:Google Colabでmanga-ocrを動かす
Colabノートブックを開いて、セルに「!pip install manga-ocr」を打つだけで環境構築が終わります。あとはMangaOcrクラスをインポートして、画像パスを投げるだけでテキストが返ってきます。
正直言って、Pythonを1行も書いたことがなくても公式READMEのコピペで動きます。Apple Silicon(M1/M2/M3)のMacなら、Zennで公開されている最適化CLIを使うとZipファイルごと一括処理できます。
上級者ルート:PaddleOCR-VL-For-Mangaで高精度運用
Hugging FaceからPaddleOCR-VL-For-Mangaを取得し、transformersかPaddleOCRで推論します。PP-DocLayoutV2と組み合わせたくなるところですが、漫画はレイアウトが独特なので、吹き出し検出は別モデル(YOLOベース等)を先に挟むのが定石です。
RTX 3060クラスのGPUがあれば自前ファインチューニングまでいけます。これは正直、特定ジャンル(例:ボクシング漫画だけ、百合漫画だけ)に特化したモデルを作れるという意味で、ニッチサイト運営者には強すぎる武器です。
精度を劇的に上げる漫画OCR実務テクニック
モデルを選んだあと、同じツールでも前処理と後処理で精度が2倍変わります。ここは現場で効いたやつだけ並べます。
- 画像は最低1200px以上にアップスケール、低解像度は誤認識の主因
- 縦書きと横書き混在時は、吹き出しごとに個別OCRを走らせる
- ルビは別行扱いになるので、後処理の正規表現で統合する
- 手書きSE(効果音)はどのモデルも苦手、セリフのみ抽出で割り切る
- 2段階抽出(領域抽出→黒塗り→再抽出)で重複を防ぐ
- 全角・半角の混在はPaddleOCR-VL-For-Mangaでも残る課題なので、正規化フィルタを必ず噛ませる
ちなみに「汎用OCRの方が安いしいいのでは?」と思った人、これはもう数字で決着ついてます。完全文認識で27%→70%、単純計算で同じ作業時間で2.6倍の成果物が出る、これは副業のROIに直撃します。
副業アフィリエイターが漫画OCRで稼ぐ具体策
ここが一番読みたいところですよね。結論、現時点で現実的に収益化できるルートは4本です。
自作漫画アフィリ素材の量産
自分が紹介したい作品(権利処理済み・自作に限る)のセリフを抽出し、ChatGPTで要約・紹介文を生成、ブログやSNSに流す。1話あたり5分で紹介記事が1本できる計算です。
ボイスコミックYouTube運用
抽出セリフをElevenLabsなどのTTSに流し込み、ショート動画化する。最近流行りの「セリフだけで魅せる1分動画」フォーマットと相性が最高です。
海外ローカライズ代行
抽出→DeepLやClaude翻訳→smart-typeで再写植、この一気通貫を受託する。Webtoon市場は2032年に710億ドル規模予測なので、上流から下流まで対応できる個人は希少性が高いです。
ニッチジャンル特化の全文検索サイト
Google Docs OCR→Spreadsheet集約→WordPress化、この流れで「特定ジャンルのセリフ全文検索サイト」を作るのも手です。もちろん権利処理済み素材に限定するのが大前提です。
副業でやるなら、ツールの使いこなしより「ジャンル選定」のほうが10倍大事です。OCRは誰でも同じ精度が出るので、差がつくのは題材と切り口。ここだけは絶対にサボらないでください。
漫画OCR自動化で守るべき著作権と法的注意点
ここは本音で言います。ツールが優秀すぎるがゆえに、一番の落とし穴になる部分です。
市販漫画のセリフを抽出して再配布・翻訳公開する行為は、日本の著作権法上、複製権・翻案権・公衆送信権の侵害に該当する可能性が極めて高いです。運用は私的利用、自作漫画、権利処理済み素材に限定してください。
- 私的利用の範囲を超える抽出・保存は原則NG
- 翻訳・二次配布はライセンス確認が必須、特にWebtoonは監視が強化中
- 商用ツール(smart-type、UPDF等)の規約で商用可否を都度確認
- AI学習データとしての利用も、元著作物の権利関係を切り離せない
じゃあどこから安全にやればいいか?答えは「自作漫画」「商用ライセンス付き素材」「パブリックドメイン」この3つだけです。ここを外した瞬間、どんなに技術的に正しくてもビジネスとして死にます。
で、最も安心で、尚且つ 漫画を一切読まず、漫画コンテンツのみをアップロードするだけで、作品の流れや構成を抜き出せる方法がこちらです。
漫画そのもののデータを抽出して、その流れを土台にして、セリフとキャラクターを再構築するツール…ANGLEX PRO
そこで今回紹介するのは、ANGLEX PROです。
これは、某無料の同人作品のサイトからダウンロードしたファイルです。
webp形式の画像ファイルで構成された作品です。
こちらをそのまま分析にかけます。
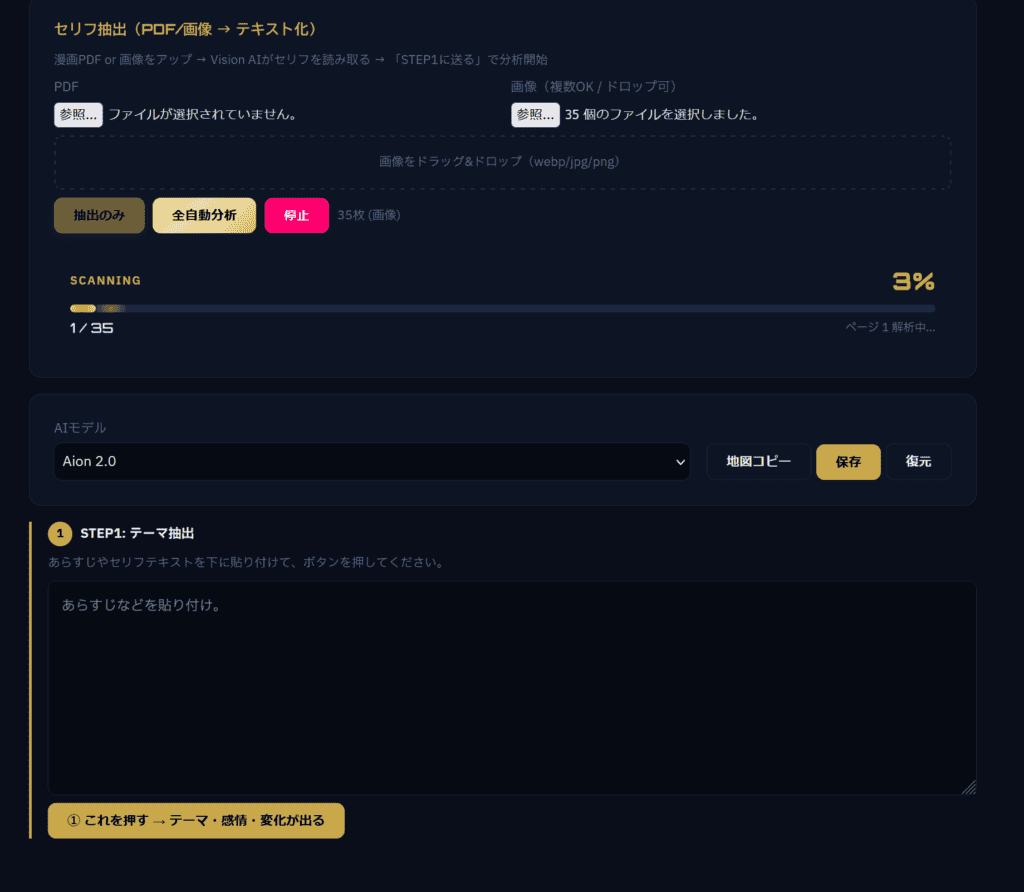
作品の中身を認識して以下のように解説が始まります。


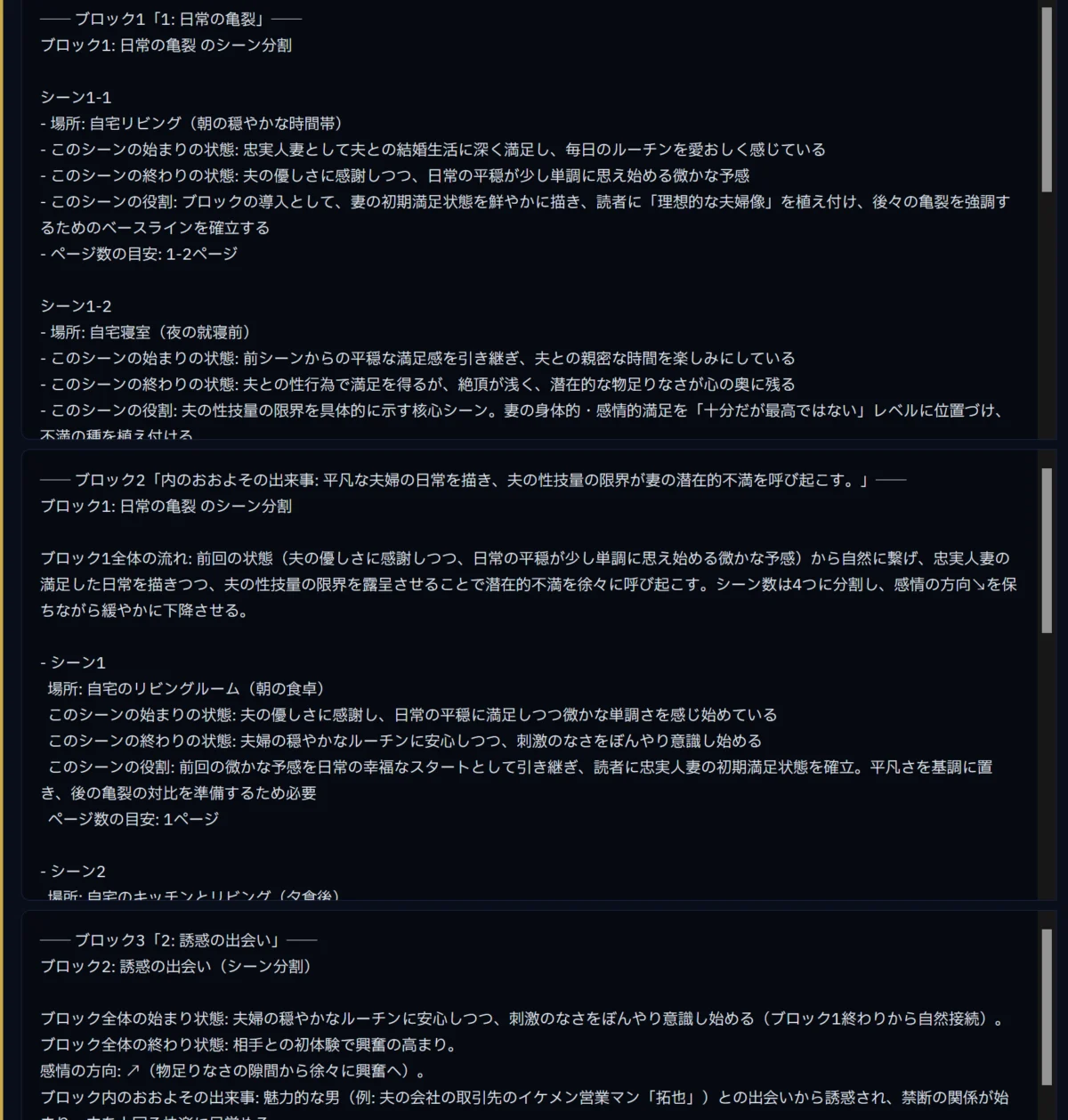
このような形で作品の全体像を抽出するイメージです。
つまり、どのように進行してシーンが進んでいるのかを分析するんです。
各シーンの役割を抽出して、再構築する‥というのがまさにこのANGLEX PROということです。
ブログ記事のリライトツールのようなものだと到底無理で、似たような語句に置き換えるリライトとは、明らかに違います。
単なる書き換え…ではなくて、分析⇒再構築です。
しかもPDF形式のみならず画像形式にも対応しているため、かなり強いです。
もちろん抽出した後も、独自の画像生成フローと機能で、エロ漫画から一般ジャンルの漫画、そして漫画×小説のハイブリッドコンテンツにも対応しています。

利用にはAIのAPIを介するツールですがコスパは最安値クラスです。
Stable DiffusionのようなオープンソースのAIの場合、GPUが必要で、使えば使うほど痛みます。
GPUが高騰する今、使いたくない人が多いと思いますが仮にGPUサーバを借りても生成に関する設定が面倒臭い事に変わりありません。
LORAがどうとか、今の時代「複雑すぎて面倒臭い」その割に、希望通りのコンテンツになるかというと時間と労力を考えるとかなり厳しいです。
ですが、ANGLEX PRO なら一瞬です。
寄せたい顔を再構築して寄せる。
そのうえでアダルトでも漫画のコマでも生成できる。
たとえば、
分析した内容を順番にコピーして貼り付けて出力したデータと、キャラクタ画像1枚をセットするだけで どんどんコピペで生成されていくんですね。
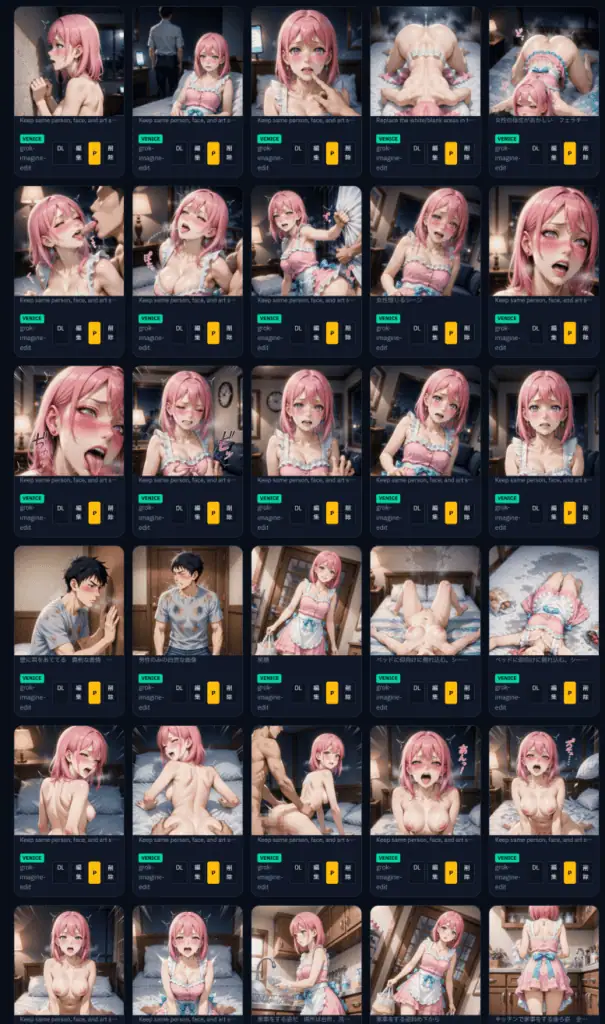
しかも1枚につき上記の画像で日本円で、1枚の通信コストは、3円前後~5円弱です。
100枚生成してもせいぜい400円~500円。
作業はコピペで絵のスキルや知識ゼロでも生成できる。
月額コストは不要でパソコン上でも環境構築すれば動作します。
ただ面倒な人はレンタルサーバでやる方が早いです。
普通にシンサーバなどで動作します。ブログなどで既に利用している場合は、そのサーバに設置可能です。
漫画セリフ自動書き起こしに関するよくある質問
- manga-ocrとPaddleOCR-VL-For-Mangaはどちらを選ぶべき?
-
導入の手軽さと安定性ならmanga-ocr、完全文認識の精度を極限まで上げたいならPaddleOCR-VL-For-Mangaです。まずmanga-ocrで運用を固めてから、不満が出た箇所だけPaddleに差し替えるのが現実的です。
- GPUがなくても漫画OCRは動きますか?
-
manga-ocrはCPUでも動作します。ただし大量処理するならGoogle Colabの無料GPUか、ローカルのRTX系を用意した方がストレスがないです。
- 効果音やオノマトペも認識できますか?
-
現時点ではどのモデルも効果音は苦手です。セリフ抽出専用と割り切り、SE部分は手動補正するか、別モデルで処理する二段構えが安全です。
- 抽出したセリフをブログに貼るのは大丈夫?
-
短い引用として著作権法の引用要件(主従関係・必然性・出典明示・改変なし)を満たすなら可能ですが、セリフだけを抜き出して羅列する構成は引用とみなされません。安全ラインは自作・許諾済み素材のみです。
これを読めば、あなたに適した稼げるツールが見つかります!
アダルトアフィリ用ツール多すぎて「どれ買えばいいか分からん」人向けに、
✅ 全7ツールを用途別に整理
✅ 阿修羅/読収のEX版ポジションも明確化
✅ WP派か静的HTML派かで分岐
までまとめた比較記事を書きました。
「最初の1本どれにするか」迷ってる人ほど刺さる内容なので、ツール検討中の人はぜひチェックしてみてください。↓↓

この記事を書いた人

関連記事
-
 TKTUBEが消えた理由 https://tktube.comが見えないアクセスできない理由
TKTUBEが消えた理由 https://tktube.comが見えないアクセスできない理由 -
アダルトアフィリエイトでAIツールを組むなら何から使う?記事・画像・動画を回す実践MAP
-
ハイブリッド副業エージェントシステム×アダルトAgentの全貌
-
検索記事だけでは弱い理由|AI時代のアダルトアフィリエイト案内設計
-
ChatGPT画像生成で同じキャラを出し続ける方法|DNAテンプレと参照画像で一貫性を上げる
-
ComfyUIでキャラクター一貫性を作るワークフロー|IP-Adapter・ControlNet・FaceSwapの組み方
-
IP-Adapterでキャラクター固定する方法|Stable Diffusionで顔と雰囲気を安定させる実務設定
-
連続誤爆の件





今すぐ無料でアダルトアフィリエイトを学ぶ。
「人間の根本的な欲求に基づくビジネスは絶対に廃れない」「稼ぎ易い。」「副業失敗者の最後の砦」
